I’ve been working with @ehaselwanter on an OpenStack deployment with Crowbar for a project we are currently doing for T-Labs.
“Scale” means different things to different people. So let us be specific here: We deployed 80 nova compute nodes and 18 Swift nodes, so that adds up to close to 100 nodes with Crowbar.
The installation from empty, humming bare metal to a running OpenStack cluster takes about 1 to 2 hours. Of course the development effort to make this work took a bit longer.
I want to share the things we learned because either nobody has done this at this scale before or if someone did they did not talk about it and/or did not share the code changes. And code changes are necessary to get it working.
The naive approach to this kind of deployment is like this: You say “What works with 5 VMs or 10 physical servers surely works with 100 servers as well”. Of course, it does not.
We identified the following problems:
Coordination problems
Crowbar uses chef in a very specific way. The Chef run on the Crowbar admin node is basically part of the Crowbar application. It takes place in the crowbar internal installation state transitioning process. This means it creates DHCP and DNS configuration in order to serve the right PXE boot configs etc.
The problem that arises at about 50 nodes (in our case) is this: - A node is in state “discovered” and is triggered to be “allocated” - This triggers a chef-client run on the to-be-installed-node as well as the admin server - The chef-client run on admin takes longer than the client-run + reboot on the to-be-installed-node which then boots again into discovery mode.
This was the basic high-level problem that we identified. I guess internally all kinds of strange things happened. The symptoms where like this:
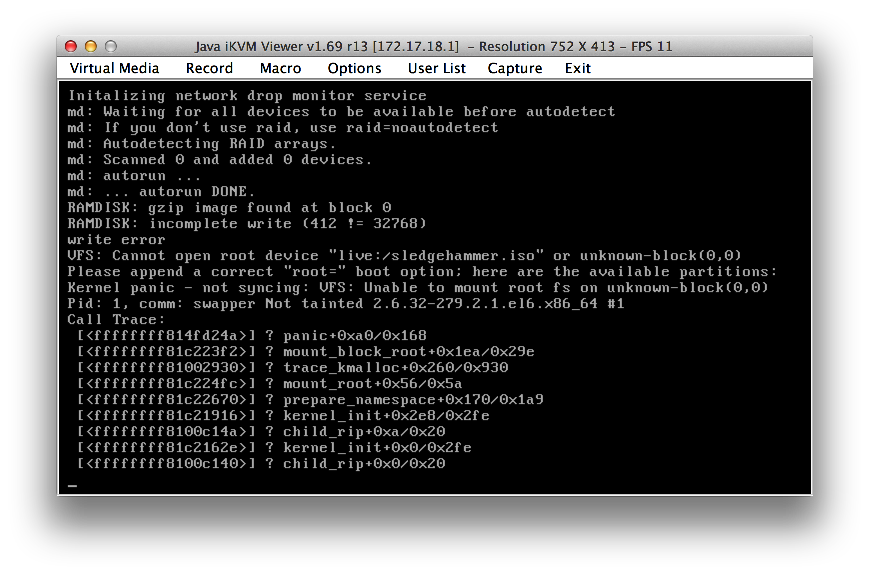
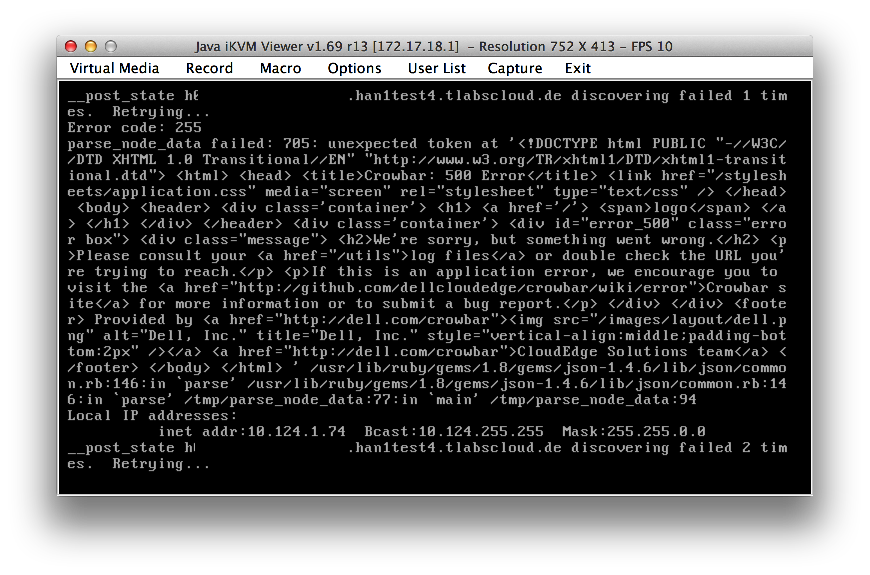
We had the following options:
a) Real solution: Coordinate state between admin node and installed node (e.g. reboot node when chef-client run on admin has succeeded and set up the installation correctly)
b) Hacky, time pressured, get-it-done solution: Make chef-client run on admin fast enough (which is the current behaviour case for smaller setups).
After we wiped our engineering tears out of our eyes when we realised there was no time for a) we went with b) and reduced the chef-client run time on the admin node from about 3-5 minutes to about 50 seconds. To find slow chef cookbooks, we used this simple script.
The fixes where quite simple: Remove unnecessary searches, make sure that e.g. DHCP, DNS and PXE boot configs only get changed, when actual changes happen. This was mostly done by enforcing order in hashes/arrays that were used to generate templates. The DNS part was a bit tricky because the “zone serial number” should only change when something else changes and it should not trigger changes itself.
Networking setup
The way the nova network config was set up, clearly was created with /24 networks in mind. With 256 hosts it does not matter if you change something for every IP in that range. With a /16 network and over 65k IPs it does matter.
The fixes here were straight forward and we actually were surprised that there were not more problems with the IP range and network configuration.
Bonding
… or how I stopped worrying about udev and love the crowbar approach. According to the documentation (as I understand it) udev is supposed to name the ethernet devices according to the MAC address. This should result in an ordered naming scheme. However, this is not what we observed.
With crowbar you can define how network cards will be addressed in the bc-network-template.json file. We use this approach to create two bonding interfaces (one for 1G and one for 10G networks). The ethX naming is not consistent across nodes, however the two 1G and two 10G interfaces are bonded and assigned to the right interface. The bonding interfaces have to be consistent across nodes (We changed crowbar to make it that way) because OpenStack refers to several network interfaces not only in the config files (which would be fine) but also in the database. With the database as central storage the naming has to be consistent so that OpenStack can find the right interfaces to do its work on.
The whole bonding setup was quite hard to get working. The reason for this is the way Ubuntu (and I guess Linux networking in general) uses the networking config files: As a way to provide command line options for several tools. This means that transitioning from one setup to another requires steps like this:
- Tear down interfaces based on current settings
- change config
- create new networking config from files
There is already a lot of code in Crowbar to orchestrate transitions from one setup to another but we had to extend some parts - and we wanted to keep the networking management parts of the distribution.
Development workflow
We do not use the Crowbar dev-tool. It does not do a lot more (that we need) that git does not do already but has a lot of assumptions about how you have to manage our code. So we just use git with git flow.
We think that git submodules are a pain to use and should be avoided in the future. Different versions of dependencies (barclamps, chef cookbooks, packages etc.) should be managed with tools like bundler, berkshelf or librarian. We’re working on a setup that uses these tools in the Crowbar context and we are glad to see that submodules already seem to have vanished from the current development branch.
For the initial setup it is fine to use the ISO installation approach. To change things on the fly (and or make Crowbar work with actual 100 nodes) we needed a way to change things quicker. Crowbar uses Chef and Chef can do that, so we just configure knife to point to the crowbar server and to include all cookbook directories from the barclamp source tree and we are good to go. A simple knife cookbook upload nova and the latest OpenStack config changes can be applied.
Screenshots
Everybody loves screenshots:
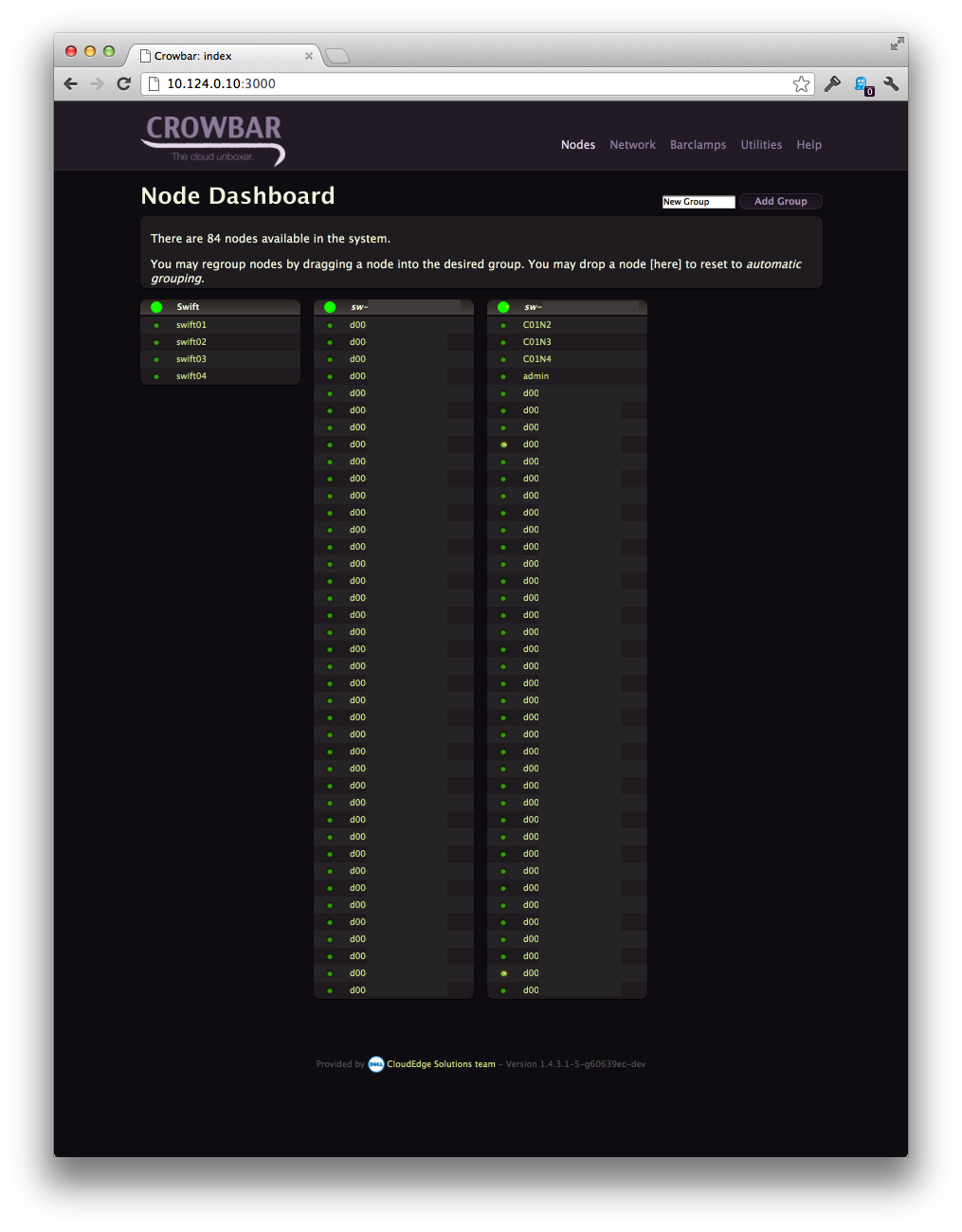
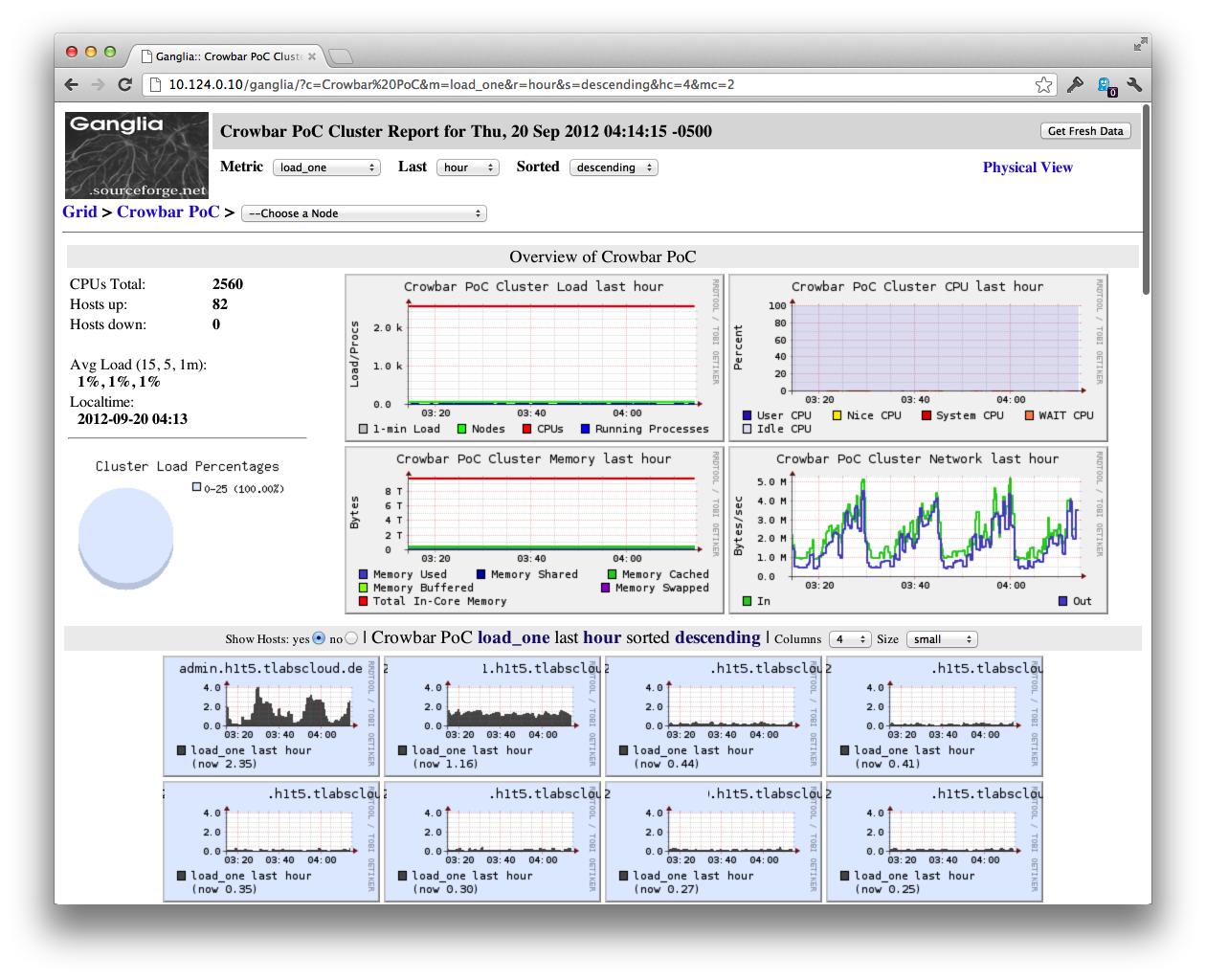
Next steps
We’ve just finished the code for internal use. It is not public yet. We will start to integrate changes to the Crowbar open source repositories in the next days.
We would love to hear or read other stories from deployments at this scale. You can reach us via Twitter @hvolkmer and @ehaselwanter
Related Posts
- Stop writing tutorials - start writing Vagrantfiles or Dockerfiles - Make use of modern tools to make tutorials understandable as well as executable
- The missing piece: Operating Systems for web scale Cloud Apps - Operating systems that are optimised for cloud applications regarding configuration support and the distributed nature of apps are not there yet.
- There will be no reliable cloud (part 3) - How I stopped worrying and love the cloud